ℹ️ Как понять, а не просто прочитать эту статью?
Во-первых, настоятельно рекомендуется читать дополнительные материалы, предложенные автором, если вы с темой до этого знакомы не были.
Во-вторых, не бойтесь прерываться, отдыхать и обдумывать прочитанное.
Тут есть два подхода, которые может предложить автор.
Можно прочитать все, чуть позже вернуться и перечитать все еще раз.
Можно читать статью понемногу, осознавая статью кусками.
⚠️ Если вы нашли какие-то ошибки в этой статье, вам что-то не понятно или вы хотите предложить улучшение, то вы всегда можете связаться с автором @mrfoxygmfr.
Задача хранения версий файлов
Представьте, что вы пишете текст доклада для конференции, редактируете фотографию в Adobe Photoshop или просто пишете какой-нибудь код. Сначала вы создаете какую-то каркасную версию, потом начинаете дополнять ее, вносить улучшения. Если вы работаете в команде, то с каждой новой версией вы делитесь исходными файлами со своими коллегами. Из-за таких операций часто появляется много копий фалов с именами подобными «Проект (1)», «Логотип copy» и т.д. Некоторые люди также стараются версионировать файлы по копиям, которыми они делятся со своими коллегами. Из-за этого накапливается множество файлов с названиями вида «Страница v.1», «Страница v.1.1», «Страница v.1.1_final», «Страница v.1.1_final_real». Концепцию, надеюсь, вы поняли.
Конечно же, такое версионирование никуда не годится, особенно при работе с кодом, расположенным в нескольких файлах. Понятно, что такими снимками состояния сложно подбирать названия, производить поиск в них, не говоря уже о коллаборации путем передачи папки, сжатой в архив. Кроме этого возникает вопрос используемых объемов памяти, потому что множество одинаковых файлов на компьютере быстро напомнит вам об ограниченности объемов вашего накопителя.
Можно ли как-то избежать всех описанных проблем, хотя бы при работе с кодом? (У нас же все-таки курс не для дизайнеров и маркетологов) Ответ прост: конечно же, ДА. Иначе почему вообще вы читаете эту статью?
Сначала дадим определение Системе контроля версий (СКВ). Это программное обеспечение, записывающее изменения в файл или набор файлов, произведенные в течении какого-то промежутка времени, и позволяющее, при необходимости, возвращаться к более ранним версиям этих файлов. Также многие системы контроля версий предлагают инструменты для совместной работы, предоставляя удобный протокол обмена данными.
История СКВ
До появления СКВ процессы разработки были основаны на рабочей папке проекта или на mail листе. Каждый раз, приходя на работу, разработчик должен был прочитать все новые заметки или письма, чтобы быть в курсе произошедших в его отсутствие изменений. О методах синхронизации рабочей копии кода остается только догадываться или узнавать из книг того времени. Например, некоторые аспекты можно прочитать в книге «Мифический человеко-месяц или как создаются программные продукты» Ф. Брукса.
Первым шагом в развитии систем контроля версий было создание локальных СКВ. Они представляли собой простейшую базу данных, которая хранит записи обо всех изменениях в файлах. Примером может служить система RCS Одним из примеров таких систем является система контроля версий RCS, которая была разработана в 1982 году. Она хранила изменения в файлах, причем для текстовых файлов (например, исходных кодов) выполняла эту задачу оптимально. Конечно же, локальные СКВ хорошо решают поставленную перед ними задачу версионирования, но даже при огромном желании коллективное использование такой системы очень трудоемко.
При решении проблемы коллективной работы возникли централизованные СКВ. Такие системы строятся вокруг одного центрального сервера. На нем хранятся изменения, и с него пользователи получают интересующие их версии. К таким системам относятся CVS, Subversion, Perforce. Их использование было стандартом на протяжении многих лет. На самом деле, такие системы удобны для использования и администрирования благодаря единственности сервера, но это одновременно является и проблемой. В случае возникновения трудностей с доступом к серверу, например, из-за отключения интернета, разработчики теряют возможность скачивать файлы. А, например, при отказе жестких дисков кодовая база теряется полностью.
Третьим поколением систем контроля версий называются распределенные СКВ. Их главное преимущество заключается в том, что разработчик скачивает себе копию репозитория вместо загрузки конкретных файлов. Копии у всех разработчиков, работающих над проектом, равноправны. Это означает, что в случае отказа восстановить кодовую базу можно будет из любого репозитория. Такие копии могут синхронизироваться между собой, что обычно выполняется с помощью сервера. Примерами распределенных СКВ могут служить Git, Mercurial, Bazaar и Darcs.
Как вы поняли по называнию статьи, мы остановимся на первой системе, которая называется Git. Проект был создан Линусом Торвальдсом для управления разработкой ядра Linux. Его первая версия выпущена 7 апреля 2005 года, он поддерживается и разрабатывается и по сей день.
Введение в git
Определение git уже дано. Про установку системы можно прочитать в данной статье. Впереди ждет еще много интересного, так что не будем расслабляться.
Как использовать git?
Для начала поговорим о том, как заставить git сохранять версии файлов.
Первое, что необходимо сделать, это конечно же создать репозиторий, в котором и будут храниться изменения.
Для этого зайдем в папку, которую мы хотим версионировать, откроем консоль и напишем команду git init.
После ее выполнения создастся новая папка с названием .git, в которой будет храниться версии файлов.
Папка является скрытой по умолчанию, так что не надо волноваться, если вы ее не нашли.
Начнем с состояний, в которых может быть файл.
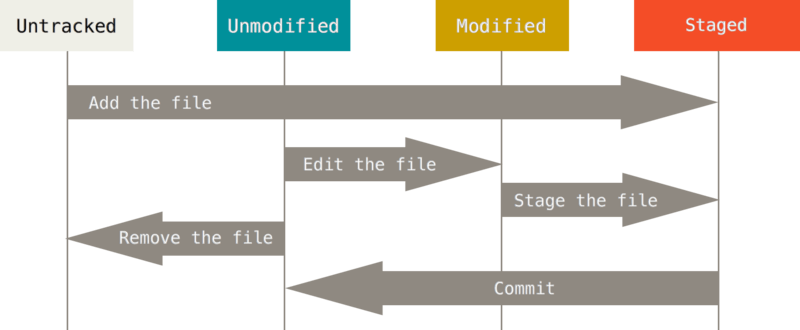 Как можно заметить из приведенного изображения, есть всего 4 состояния:
Как можно заметить из приведенного изображения, есть всего 4 состояния:
- Untracked — файл не версионируется;
- Unmodified — файл не изменялся относительно последней версии;
- Modified — в файл были внесены изменения;
- Staged — файл был создан или изменен, эти изменения будут сохранены в следующей версии.
Далее назовем несколько важных терминов:
- Working tree — (досл. рабочее дерево) папка, в которой был инициализирован репозиторий;
- Staging area или Index — область, в которой хранятся изменения, выбранные для сохранения (создания коммита);
- Commit — снимок состояния папки.
Как же происходит управление версиями?
Обратим внимание на приведенную выше картинку и рассмотрим путь файла в системе.
Сначала создадим файл в рабочей папке (или working tree), например, с помощью редактора кода.
Потом мы можем посмотреть изменения с помощью команды git status.
Видим, что созданный файл main.cpp находится в состоянии untracked.
С помощью команды git add (про аргументы всех команд мы поговорим позже) добавим его в index.
Теперь вывод команды git status будет другой.
Далее можно создать коммит с помощью команды git commit, что сохранит все изменения, внесенные в index.
Посмотрев на статус репозитория, мы увидим, что новых изменений нет, а команда git log показывает созданный коммит.
$ git init
Initialized empty Git repository in /home/mrfoxygmfr/test
$ vim main.cpp
$ git status
On branch master
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
main.cpp
nothing added to commit but untracked files present (use "git add" to track)
$ git add main.cpp
$ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: main.cpp
$ git commit -m "initial commit"
$ git status
On branch master
nothing to commit, working tree clean
$ git log
commit b0400542ca79828b47c63f7c7ab97f30b806e840 (HEAD -> master)
Author: mrfoxygmfr <mrfoxygmfr@mrfoxygmfr.ru>
Date: Sat Jan 01 00:00:00 2023 +0300
initial commit
Теперь давайте изменим файл main.cpp, добавим еще один файл и создадим коммит.
В логе появился еще один снимок состояния, а вызвав команду git diff, мы можем увидеть различия между файлами.
$ vim main.cpp
$ vim file2.txt
$ git add main.cpp file2.txt
$ git status
On branch master
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
new file: file2.txt
modified: main.cpp
$ git commit -m "commit 2"
$ git log
commit f87aa9d3d7b1aa7748c0e83e3277aec12c27c956 (HEAD -> master)
Author: mrfoxygmfr <mrfoxygmfr@mrfoxygmfr.ru>
Date: Mon Jan 02 00:00:00 2023 +0300
commit 2
commit b0400542ca79828b47c63f7c7ab97f30b806e840 (HEAD -> master)
Author: mrfoxygmfr <mrfoxygmfr@mrfoxygmfr.ru>
Date: Sat Jan 01 00:00:00 2023 +0300
initial commit
$ git diff b0400
diff --git a/file2.txt b/file2.txt
new file mode 100644
index 0000000..6c493ff
--- /dev/null
+++ b/file2.txt
@@ -0,0 +1 @@
+file2
diff --git a/main.cpp b/main.cpp
index 9daeafb..7e72ab4 100644
--- a/main.cpp
+++ b/main.cpp
@@ -1 +1,7 @@
-test
+#include <bits/stdc++.h>
+using namespace std;
+
+int32_t main() {
+ cout << "Hello, world!";
+ return 0;
+}
Написав команду git checkout, мы можем переключиться на старую версию и посмотреть старое состояние файла.
Заметьте, мы перешли в состояние detached HEAD, об этом поговорим чуть позже.
$ git checkout b04005
You are in 'detached HEAD' state.
...
HEAD is now at b040054 initial commit
$ ls
main.cpp
$ cat main.cpp
test
Мы рассмотрели стандартный пример, демонстрирующий базовые команды git. Далее в статье мы изучим наиболее используемые команды. Если вы хотите изучить детально аргументы команды, то вам стоит обратиться к утилите man или онлайн документации.
Автор рекомендует факультативно прочитать данную книгу. Если вам не известна система git, то для изучения основ настоятельно рекомендуется прочитать части со 2 по 5. Части 7-8 могут быть прочитаны для изучения методов углубленного применения, а информация 10 части используется в данной статье.
В данной же статье раскрывается внутренняя архитектура системы.
«Сантехника» и «Фарфор»
В предыдущем параграфе вы могли познакомиться с некоторыми командами git. Такие команды предоставляют удобный интерфейс пользователю. Их создатели системы git называли porcelain commands или фарфоровые команды. Еще их называют высокоуровневыми командами.
Раз есть высокоуровневые команды, то должны быть низкоуровневые. Авторы системы называли их plumbing commands или сантехническими командами.
Зачем нужно это разделение?
Понятно, что конечные пользователи пользуются по большей части высокоуровневыми командами, такими как git commit, git checkout, git add.
Как и многие другие программы, git развивается и пытается удовлетворять большинству требований, предоставляемых пользователями.
Пока это так, высокоуровневые команды могут меняться, улучшая качество и удобство «фарфора».
Некоторым пользователям необходима стабильность и однозначность для написания своих скриптов, где-то им, может быть, необходимо другое поведение высокоуровневых команд. Тогда они могут построить свой «фарфор» поверх «сантехники», которую предоставляет git.
Вообще говоря, такое разделение позволяет улучшать git, писать свои консольные и графические клиенты удобными методами.
Список команд и их разделение на «фарфор» и «сантехнику» можно изучить здесь.
Детальное погружение в git
Чем может быть полезно изучение внутренней архитектуры git?
Как минимум, понимание внутренней архитектуры позволит отвечать на некоторые вопросы, появляющиеся в процессе использования. Это даст возможность использовать систему в большем количестве случаев, а, значит, принесет удобство.
Конечно, лучше всегда иметь какой-либо наглядный пример, от которого можно будет оттолкнуться. Поэтому, основной задачей на эту статью станет создание git репозитория с нуля с помощью лишь plumbing commands и некоторых других стандартных утилит.
Внутреннее устройство
Пришло время перейти к ответу на самый интересный вопрос, а как же git хранит изменения?
Для этого необходимо понять, что же за файлы хранятся в папке .git.
Конечно, это формально расписано в документации, из которой вы можете узнать о неупомянутых в статье папках и файлах.
Предлагаю вам совместить решение задачи, которую мы поставили ранее, с изучением данного вопроса.
Контролировать успешность создания репозитория будем с помощью команды git status, не изменяющей никаких файлов.
Начнем с чистого листа. Все команды, которые будут приведены далее, выполнялись последовательно, если не оговорено обратное.
$ pwd
/home/mrfoxygmfr
$ mkdir my_git_repo
$ cd my_git_repo
$ mkdir .git
$ pwd
/home/mrfoxygmfr/my_git_repo
$ echo "Hello, world" > main.txt
$ echo "File2" > file2.txt
$ mkdir backups
$ echo "File2 previous" > backups/file2.txt
$ git status
fatal: not a git repository (or any of the parent directories): .git
Увы, существование папки .git не является показателем того, что это репозиторий. Давайте создадим все необходимые файлы, а далее разберемся, что они означают.
$ mkdir .git/objects
$ mkdir .git/refs
$ mkdir .git/refs/heads
$ echo "ref: refs/heads/master" > .git/HEAD
$ git status
On branch master
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
backups/
file2.txt
main.txt
nothing added to commit but untracked files present (use "git add" to track)
$ tree .git
.git
├── HEAD
├── objects
└── refs
└── heads
Ура, получилось! Получается, что четыре папки и один файл — минимум для репозитория.
Рассмотрим данные, хранимые в репозитории, в порядке важности.
Объекты
Первыми, конечно же, будут объекты — элементы, с помощью которых и сохраняются версии. Объекты бывают четырех типов: blob, tree, commit и tag. Хранятся объекты внутри папки .git/objects, которая обязательно должна присутствовать в репозитории. Забежим немного вперед, объекты blob и tree создают структуру подобную файловой системе.
Каждый объект представляется в памяти в виде заголовка и содержимого, сжатого алгоритмом zlib. Заголовок состоит из типа объекта (blob, tree, commit или tag), размера содержимого в байтах и терминирующего заголовок нулевого байта. Рассмотрим на примере, пусть у нас есть строка “Hello, world”, записанная в какой-то файл. Тогда содержимое файла будет кодироваться типом blob, об этом вы узнаете чуть позже. Заголовок для этого объекта будет иметь вид “blob 12\u0000”, а все содержимое объекта перед сжатием так: “blob 12\u0000Hello, world”. Здесь \u0000 означает нулевой байт.
Логично, что объекты должны иметь уникальные идентификаторы. В git в их роли выступает значение хеш-функции SHA-1, примененной к байтовому представлению данных объекта до сжатия. Для нашего примера объект будет иметь хеш a5c19667710254f835085b99726e523457150e03, причем он не изменится в зависимости от компьютера или времени создания файла. Далее в статье под id объекта будет подразумеваться значение хеша объекта.
Произведите серию команд в консоли и удостоверьтесь, что их вывод будет совпадать.
Обратите внимание, эти команды не относятся к основному повествованию. Здесь создается новый репозиторий, файл с содержимым “Hello, world”, он добавляется в index и создается commit.
После этого можно наблюдать файл объекта с хешом a5c19667710254f835085b99726e523457150e03 в папке объектов.
Просмотр содержимого объекта с помощью команды Проведите эксперимент и проверьте вышеизложенное (см. выпадающий блок)
git cat-file выдаст “Hello, world”, что еще раз подтверждает вышеизложенное.$ git init
$ echo "Hello, world" > main.txt
$ git add main.txt
$ git commit -m "test"
$ ls .git/objects/a5
c19667710254f835085b99726e523457150e03
$ git cat-file -p a5c19667710254f835085b99726e523457150e03
Hello, world
Обратите внимание, что git берет первые два символа хеша и создает папку с таким названием, а потом создает файл в этой папке, который называет остатком хеша. Это оптимизация, позволяющая облегчить поиск нужного объекта как файла. Без этого операционной системе, в худшем случает, нужно было бы проверить все входящие в папку файлы, количество которых равно количеству объектов. В данном же случае задача ускоряется в 256 раз, потому что сначала среди папок находится нужная, это не более 256 операций. Это время можно принять за некую константу, не влияющую на расчеты при больших количествах объектов. Далее, в каждой папке будет примерно равное количество файлов из-за особенностей хеш-функции.
Важное замечание. Обычно первых 4-10 символов хеша хватает, чтобы найти нужный объект, особенно в случае небольших репозиториев. Поэтому большинство команд может быть вызвано с укороченным размером хеша. Так поступает, например, github, который показывает лишь 7 символов хеша, потому что вероятность их совпадения много мала.
Пришло время познакомится с первой низкоуровневой командой git cat-file (-p | -t) <object>.
Конечно, это не вся семантика, но ее будет вполне достаточно для текущей статьи.
Примеры вывода команды вы увидите чуть позже.
Объекты типа blob
BLOB расшифровывается как binary large object или двоичный большой объект. Фактически, это просто массив байт. В СУБД он часто используется для хранения различных файлов, например, аватарок пользователей. Git использует его схоже с СУБД, храня в объектах такого типа содержимое файлов.
Вообще говоря, мы можем считать за файл в файловой системе непрерывный кусок памяти.
Это абсолютно верно, если положить, что за название, метаданные и права доступа отвечает какой-то другой блок фс.
Тогда объект типа blob можно назвать файлом внутренней файловой системы git.
Формально же, под содержимым объекта типа blob подразумевается содержимое исходного файла, взятого в двоичном виде.
Объекты типа blob можно создать с помощью низкоуровневой команды git hash-object [-t <type>] [-w] <file>.
Если вы не укажете тип в качестве аргумента, то он автоматически будет установлен как blob.
Добавление аргумента -w заставляет git записать полученный объект в базу объектов.
Выводом команды является хеш, идентифицирующий объект.
$ git hash-object -w main.txt
a5c19667710254f835085b99726e523457150e03
$ git hash-object -t blob -w file2.txt
b973e639605e63466ea5ba09b04a545f16946ca8
$ git hash-object -w backups/file2.txt
037918cc6cd355be9475f80de225addba810395d
Далее посмотрим на результаты:
$ git status
On branch master
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
backups/
file2.txt
main.txt
nothing added to commit but untracked files present (use "git add" to track)
$ tree -a .
.
├── .git
│ ├── HEAD
│ ├── objects
│ │ ├── 03
│ │ │ └── 7918cc6cd355be9475f80de225addba810395d
│ │ ├── a5
│ │ │ └── c19667710254f835085b99726e523457150e03
│ │ └── b9
│ │ └── 73e639605e63466ea5ba09b04a545f16946ca8
│ └── refs
│ └── heads
├── backups
│ └── file2.txt
├── file2.txt
└── main.txt
9 directories, 7 files
Видим, что у нас появилось 3 новых объекта.
Изменения же, исходя из вывода команды git status, записаны не были.
Объекты типа tree
Вспомним теорию графов, которая изучается в дискретной математике и довольно часто применяется в программировании. Если же вы не знакомы с ней, то не беспокойтесь. Нам потребуется самый минимум — пара определений, которые можно осознать на картинках, например, из этой статьи. Представим, что у нас есть ациклический связный граф, в котором количество ребер меньше количества вершин на одну. Такой граф называется деревом. В нем всегда можно выбрать какую-нибудь вершину, которую назовем корнем.
Вообще говоря, файловая система (без ссылок и ярлыков) является деревом. Корневой вершиной будет / в аналогии с unix-подобными ОС или C:/ в аналогии с windows. Ребром графа будет являться название файла или папки. Переходя по ребру мы будем переходить к вершине, отвечающей за папку или файл с соответствующим названием.
В случае git, объекты tree будут вершинами дерева, отвечающими за папки. Корневую вершину тоже можно считать папкой. В качестве содержимого будут храниться ребра — указатели на следующие вершины дерева.
Просмотр дерева можно выполнять командами git ls-tree, git cat-fileg
Вообще, создать дерево можно несколькими способами.
Например, создать дерево по «описанию» (выводу команды git ls-tree).
$ echo "100644 blob 037918cc6cd355be9475f80de225addba810395d file2.txt" | git mktree
3a04a188189688e994e475b5d63e37e25c1903ed
$ git ls-tree 3a04a188189688e994e475b5d63e37e25c1903ed
100644 blob 037918cc6cd355be9475f80de225addba810395d file2.txt
$ git status
On branch master
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
backups/
file2.txt
main.txt
nothing added to commit but untracked files present (use "git add" to track)
Также можно создавать дерево по содержимому в staging area. Заметьте, что мы добавим в качестве файла backups/file2.txt хеш объекта файла, а не дерева. Это особенность index, про который речь зайдет позже.
$ git update-index --add --cacheinfo 100644 a5c19667710254f835085b99726e523457150e03 main.txt
$ git update-index --add --cacheinfo 100644 b973e639605e63466ea5ba09b04a545f16946ca8 file2.txt
$ git update-index --add --cacheinfo 100644 037918cc6cd355be9475f80de225addba810395d backups/file2.txt
$ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: backups/file2.txt
new file: file2.txt
new file: main.txt
$ git write-tree
bafcdbe15fbb2ac14ec033454fde52b052497663
$ git ls-tree bafcdbe15fbb2ac14ec033454fde52b052497663
040000 tree 3a04a188189688e994e475b5d63e37e25c1903ed backups
100644 blob b973e639605e63466ea5ba09b04a545f16946ca8 file2.txt
100644 blob a5c19667710254f835085b99726e523457150e03 main.txt
$ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: backups/file2.txt
new file: file2.txt
new file: main.txt
Как можно заметить, объект дерева, который мы создали ранее, используется в новом дереве. Во-первых, это означает, что дерево зависит только от хешей файлов и папок, которые в него входят. Во-вторых, если какое-то поддерево не изменяется, то будет переиспользован ранее созданный объект.
Текущую имеющуюся структуру можно представить так:
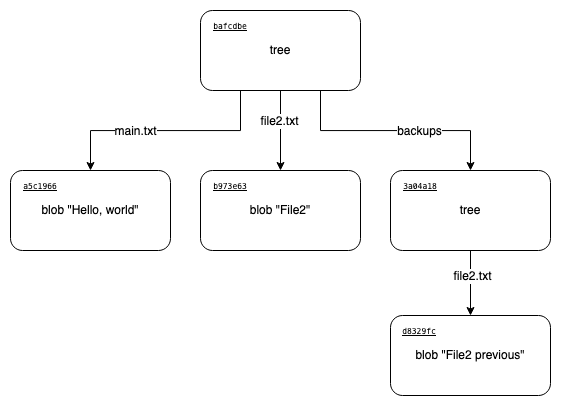
Объекты типа commit
Но все же, дерево создано, файлы сохранены, а статус изменений не поменялся.
Необходимо понять, что же такое коммит с точки зрения системы git. Создадим его и посмотрим на структуру. Используя лишь низкоуровневые команды, коммит можно создать, передав id объекта дерева, являющегося корнем директории.
$ git commit-tree -m "initial commit" bafcdbe
96735953905e065a26f3529ec9d47e6cbf3bcdb4
$ git cat-file -p 96735953905e065a26f3529ec9d47e6cbf3bcdb4
tree bafcdbe15fbb2ac14ec033454fde52b052497663
author mrfoxygmfr <mrfoxygmfr@sch9.ru> 1675090524 +0500
committer mrfoxygmfr <mrfoxygmfr@sch9.ru> 1675090524 +0500
initial commit
$ git status
On branch master
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: backups/file2.txt
new file: file2.txt
new file: main.txt
$ git log
fatal: your current branch 'master' does not have any commits yet
Видим, что коммит состоит из хеша дерева, автора изменений, времени и сообщения. Вообще говоря, в коммите должен присутствовать еще и хеш предка, но так как мы создаем первый коммит, то он отсутствует. Еще нужно сказать, что хешей предков может быть несколько. Если произошла такая ситуация, то такой коммит называется merge коммитом. Обычно, они появляются при слиянии нескольких веток в одну. Вообще говоря, в таком случае дерево коммитов представляет DAG.
Но все же изменения считаются не записанными! Казалось, коммит же создан, но не все так просто.
Небольшое отступление, git commit создает дерево для коммита из объединения последней версии и изменений, внесенных в staging area.
Это означает, что пользователь может регулировать изменениями, вносимыми в коммит.
Указатели или refs
Пришло время узнать, что же находится в папке refs. Из названия можно предположить, что в этой папке должны храниться указатели на какие-то объекты, и это будет абсолютно верным утверждением. Обычно, она состоит из двух папок: heads (головы веток) и tags (теги). Файлы, хранящиеся в этих папках, имеют название соответственно тега или ветки и содержат лишь хеш объекта, на который указывают.
Указатели на ветки или refs/heads
В папке heads, находятся указатели на последние объекты типа commit различных веток. Фактически, ветка в гите — указатель на последний коммит в данной ветке. Можно заметить, что тут используется идея односвязного списка. Вспомним, что у коммитов всегда есть хотя бы один родитель. Фактически, выполняя коммит, мы создаем новый объект и двигаем указатель текущей используемой ветки на него, причем все предыдущие коммиты остаются достижимыми по ссылкам. Это означает, что git сможет вывести историю всех коммитов, от последнего к первому.
Легко догадаться, что создание коммита через git commit-tree не добавляет его в ветку.
Или, говоря правильно, не передвигает указатель ветки на нужный коммит.
Работая с низкоуровневыми командами, пользователь должен сделать это отдельной командой.
$ git update-ref refs/heads/master 96735953905e065a26f3529ec9d47e6cbf3bcdb4
$ git status
On branch master
nothing to commit, working tree clean
$ git log
gcommit 96735953905e065a26f3529ec9d47e6cbf3bcdb4 (HEAD -> master)
Author: mrfoxygmfr <mrfoxygmfr@sch9.ru>
Date: Mon Jan 30 19:55:24 2023 +0500
initial commit
$ tree -a .
.
├── .git
│ ├── HEAD
│ ├── index
│ ├── logs
│ │ ├── HEAD
│ │ └── refs
│ │ └── heads
│ │ └── master
│ ├── objects
│ │ ├── 03
│ │ │ └── 7918cc6cd355be9475f80de225addba810395d
│ │ ├── 3a
│ │ │ └── 04a188189688e994e475b5d63e37e25c1903ed
│ │ ├── 96
│ │ │ └── 735953905e065a26f3529ec9d47e6cbf3bcdb4
│ │ ├── a5
│ │ │ └── c19667710254f835085b99726e523457150e03
│ │ ├── b9
│ │ │ └── 73e639605e63466ea5ba09b04a545f16946ca8
│ │ └── ba
│ │ └── fcdbe15fbb2ac14ec033454fde52b052497663
│ └── refs
│ └── heads
│ └── master
├── backups
│ └── file2.txt
├── file2.txt
└── main.txt
15 directories, 14 files
Отлично, изменения добавлены, версия создана, но знакомство на этом не заканчивается.
Поговорим про теги, их объекты и указатели.
Объекты типа tag
Как может показаться, всех ранее приведенных объектов достаточно для использования системы git с задачей контроля версий. Вообще говоря, это утверждение применимо и для первых двух типов объектов (blob и tree), но тогда возникает вопрос в хранении комментариев, авторов изменений и истории. Конечно же, можно дополнить объекты типа tree необязательными полями, но это усложнит реализацию и приведет к некоторым другим конфликтам. Так и здесь, теги выделены в отдельные объекты для облегчения реализации.
Представьте, что вы сделали несколько коммитов и выпустили программу в этой версии. Логично, что вы захотите отметить это состояние изменений как версию программы и написать комментарий, что реализованно к текущему моменту. Если сказать, что тег это просто коммит, то тогда в качестве комментария будет использоваться комментарий последнего коммита, например, bugfix in config-parse.py, что вообще не передает смысл версии. Именно по такому принципу и появился отдельный объект для тега.
Давайте создадим объект tag с помощью низкоуровневых команд.
Аналогично git mktree существует команда git mktag, принимающая через stdin строго отформатированное содержимое тега.
$ echo "object 96735953905e065a26f3529ec9d47e6cbf3bcdb4\ntype commit\ntag first-commit\ntagger mrfoxygmfr <mrfoxygmfr@sch9.ru> 1675090524 +0500\n\ntag message"
object 96735953905e065a26f3529ec9d47e6cbf3bcdb4
type commit
tag first-commit
tagger mrfoxygmfr <mrfoxygmfr@sch9.ru> 1675090524 +0500
tag message
$ echo "object 96735953905e065a26f3529ec9d47e6cbf3bcdb4\ntype commit\ntag first-commit\ntagger mrfoxygmfr <mrfoxygmfr@sch9.ru> 1675090524 +0500\n\ntag message" | git mktag
38c3c8dc6be8437452fe9fb71b8cc5a97627b3b6
$ git show 38c3c8dc6be8437452fe9fb71b8cc5a97627b3b6
tag first-commit
Tagger: mrfoxygmfr <mrfoxygmfr@sch9.ru>
Date: Mon Jan 30 19:55:24 2023 +0500
tag message
commit 96735953905e065a26f3529ec9d47e6cbf3bcdb4 (HEAD -> master)
Author: mrfoxygmfr <mrfoxygmfr@sch9.ru>
Date: Mon Jan 30 19:55:24 2023 +0500
initial commit
diff --git a/backups/file2.txt b/backups/file2.txt
new file mode 100644
index 0000000..037918c
--- /dev/null
+++ b/backups/file2.txt
@@ -0,0 +1 @@
+File2 previous
diff --git a/file2.txt b/file2.txt
new file mode 100644
index 0000000..b973e63
--- /dev/null
+++ b/file2.txt
@@ -0,0 +1 @@
+File2
diff --git a/main.txt b/main.txt
new file mode 100644
index 0000000..a5c1966
--- /dev/null
+++ b/main.txt
@@ -0,0 +1 @@
+Hello, world
$ git show first-commit
fatal: ambiguous argument 'first-commit': unknown revision or path not in the working tree.
Use '--' to separate paths from revisions, like this:
'git <command> [<revision>...] -- [<file>...]'
Рассмотрим содержимое объекта. Здесь есть название тега, его создатель, комментарий и хеш коммита, на который указывает данный тег.
Как легко видеть, обратиться к содержимому по id объекта тега получилось, чего нельзя сказать об обращении по названию. Ответ на эту загадку прост — для обращения к чему-либо по названию необходим указатель.
Указатели на теги или refs/tags
Как вы могли догадаться, папка tags содержит указатели на объекты типа tag, но это не полностью верно. Есть два вида тегов: обычные, которые указывают на объекты типа tag, и легковесные, указывающие на объекты типа commit. Различие заключается в том, что легковесные теги можно рассматривать как неизменяемые ветки. Использование легковесных тегов удобно для локальных отметок каких-то старых изменений, к которым планируется частый доступ. Например, для доступа к старым версиям удаленных или модифицированных файлов.
Создадим два указателя с помощью низкоуровневых команд:
$ git update-ref refs/tags/first-commit 38c3c8dc6be8437452fe9fb71b8cc5a97627b3b6
$ git update-ref refs/tags/first-commit-lw 96735953905e065a26f3529ec9d47e6cbf3bcdb4
$ git show first-commit
tag first-commit
Tagger: mrfoxygmfr <mrfoxygmfr@sch9.ru>
Date: Mon Jan 30 19:55:24 2023 +0500
tag message
commit 96735953905e065a26f3529ec9d47e6cbf3bcdb4 (HEAD -> master, tag: first-commit-lw, tag: first-commit)
Author: mrfoxygmfr <mrfoxygmfr@sch9.ru>
Date: Mon Jan 30 19:55:24 2023 +0500
initial commit
diff --git a/backups/file2.txt b/backups/file2.txt
new file mode 100644
index 0000000..037918c
--- /dev/null
+++ b/backups/file2.txt
@@ -0,0 +1 @@
+File2 previous
diff --git a/file2.txt b/file2.txt
new file mode 100644
index 0000000..b973e63
--- /dev/null
+++ b/file2.txt
@@ -0,0 +1 @@
+File2
diff --git a/main.txt b/main.txt
new file mode 100644
index 0000000..a5c1966
--- /dev/null
+++ b/main.txt
@@ -0,0 +1 @@
+Hello, world
$ git show first-commit-lw
commit 96735953905e065a26f3529ec9d47e6cbf3bcdb4 (HEAD -> master, tag: first-commit-lw, tag: first-commit)
Author: mrfoxygmfr <mrfoxygmfr@sch9.ru>
Date: Mon Jan 30 19:55:24 2023 +0500
initial commit
diff --git a/backups/file2.txt b/backups/file2.txt
new file mode 100644
index 0000000..037918c
--- /dev/null
+++ b/backups/file2.txt
@@ -0,0 +1 @@
+File2 previous
diff --git a/file2.txt b/file2.txt
new file mode 100644
index 0000000..b973e63
--- /dev/null
+++ b/file2.txt
@@ -0,0 +1 @@
+File2
diff --git a/main.txt b/main.txt
new file mode 100644
index 0000000..a5c1966
--- /dev/null
+++ b/main.txt
@@ -0,0 +1 @@
+Hello, world
Тег first-commit указывает на объект типа tag, поэтому кроме объекта коммита мы увидели сообщение, сохраненное в объекте тега. Тег first-commit-lw же отсылает на объект типа commit, поэтому содержит информацию только о нем.
В чем вообще цель существования указателей на объекты? Логично, что просмотреть все возможные объекты на больших репозиториях не является легкой задачей. А если еще необходимо определить, какие из них являются конечными, то такая задача будет требовать либо много времени, либо много памяти. Поэтому, на все конечные коммиты должны указывать какие-то указатели, иначе такая ветка будет недостижимой без знания хешей соответствующих коммитов.
Вообще, создавать указатели можно и простым изменением соответствующего файла.
Команда git update-ref же позволяет добавить некоторые проверки.
Например, у вас не получится создать ветку, указывающую не на коммит.
$ git update-ref refs/heads/first-commit-br 38c3c8dc6be8437452fe9fb71b8cc5a97627b3b6
fatal: update_ref failed for ref 'refs/heads/first-commit-br': cannot update ref 'refs/heads/first-commit-br': trying to write non-commit object 38c3c8dc6be8437452fe9fb71b8cc5a97627b3b6 to branch 'refs/heads/first-commit-br'
Файл HEAD
Обычно, одна из веток git считается рабочей веткой и все изменения происходят именно с ней. Как мы поняли из предыдущего пункта, ветки это просто указатели на последние объекты и никакого интерфейса для пометки об использовании ветки они не предоставляют. Для этого и используется файл HEAD, указывающий на ветку, с которой сейчас будут происходить изменения. Фактически, HEAD это указатель на текущую ветку (или указатель на указатель).
Содержимое файла обычно выглядит так:
$ cat .git/HEAD
ref: refs/heads/master
Это содержимое показывает, что сейчас используется ветка master.
Но зачем тогда в файле написано ref, еще и полный путь до файла с веткой? Можно же было просто написать master и было бы понятно, что HEAD указывает на ветку master.
Конечно же, не все так просто.
Существует такое понятие как detached HEAD.
Это состояние, в котором HEAD указывает не на ветку, а на какой-то коммит.
Такое может произойти, когда вы перемещаетесь по истории с помощью команды git checkout.
Рассмотрим поподробнее:
$ git checkout first-commit
Note: switching to 'first-commit'.
You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by switching back to a branch.
If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -c with the switch command. Example:
git switch -c <new-branch-name>
Or undo this operation with:
git switch -
Turn off this advice by setting config variable advice.detachedHead to false
HEAD is now at 9673595 initial commit
$ git log
commit 96735953905e065a26f3529ec9d47e6cbf3bcdb4 (HEAD, tag: first-commit-lw, tag: first-commit, master)
Author: mrfoxygmfr <mrfoxygmfr@sch9.ru>
Date: Mon Jan 30 19:55:24 2023 +0500
initial commit
$ cat .git/HEAD
96735953905e065a26f3529ec9d47e6cbf3bcdb4
Заметьте, сейчас вместо HEAD -> master отображается HEAD, master.
Это означает как раз состояние detached HEAD.
Это состояние ничем не отличается от указателя на ветку, пока вы не начинаете вносить изменения в историю. Допустим, вы создаете коммит в таком состоянии, тогда объект будет создан по тем же правилам, но вместо изменения указателя ветки, у вас изменится указатель HEAD. Кажется, что поведение не изменилось, поменялся лишь указатель, но это конечно же не так. Как легко догадаться, при изменении указателя HEAD изменения, созданные в данном состоянии, будут утеряны по причине того, что на них не указывает ни один указатель. Поэтому, после внесения изменений в таком состоянии необходимо создать новую ветку или tag или сохранить где-то хеш последнего коммита.
Немного отойдем от концепции использования низкоуровневых команд и создадим еще один коммит, но уже высокоуровневыми командами.
$ echo "new file" > new_file.txt
$ git add new_file.txt
$ git status
HEAD detached at first-commit
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
new file: new_file.txt
$ git commit -m "second commit (by porcelain)"
[detached HEAD ca84f5a] second commit (by porcelain)
1 file changed, 1 insertion(+)
create mode 100644 new_file.txt
$ git log
commit ca84f5a1ec1ae427566540b3c85af2da56fc85e7 (HEAD)
Author: mrfoxygmfr <mrfoxygmfr@sch9.ru>
Date: Tue Jan 31 14:35:24 2023 +0500
second commit (by porcelain)
commit 96735953905e065a26f3529ec9d47e6cbf3bcdb4 (tag: first-commit-lw, tag: first-commit, master)
Author: mrfoxygmfr <mrfoxygmfr@sch9.ru>
Date: Mon Jan 30 19:55:24 2023 +0500
initial commit
Как упоминалось ранее, если сейчас мы перейдем к ветке, то потеряем созданный коммит.
$ git checkout master Downloads/my_repo HEAD
Warning: you are leaving 1 commit behind, not connected to
any of your branches:
ca84f5a second commit (by porcelain)
If you want to keep it by creating a new branch, this may be a good time
to do so with:
git branch <new-branch-name> ca84f5a
Switched to branch 'master'
$ git log
commit 96735953905e065a26f3529ec9d47e6cbf3bcdb4 (HEAD -> master, tag: first-commit-lw, tag: first-commit)
Author: mrfoxygmfr <mrfoxygmfr@sch9.ru>
Date: Mon Jan 30 19:55:24 2023 +0500
initial commit
$ git status
On branch master
nothing to commit, working tree clean
Заметьте, команда git status не выводит ничего, потому что при git checkout working tree устанавливается в состояние коммита.
Если бы мы просто передвинули указатель с помощью git update-ref или прямым изменением файла, то git status сигнализировала бы нам о существовании файла в состоянии staged.
Файл index
Еще один важный файл в папке .git это index. Из его названия понятно, что он содержит информацию о staging area. Его формат строго типизирован и описан в документации. Для нашей статьи и полноценного использования git будет достаточно этих поверхностных знаний.
Запаковка изменений и оптимальность хранения
Как могло показаться из принципа создания объектов, git хранит изменения прямым копированием файлов, то есть почти ничем не отличается от последовательности файлов _ver1, _ver2 и т.д. Конечно же, это не так, иначе почему git обладает такой популярностью.
Конечно, вся вышеизложенная информация про объекты остается верной. Хранение объектов в таком формате называется «свободным» («loose») форматом.
Раз в некоторое время, при загрузке изменений на удаленный репозиторий или при выполнении команды git gc происходит запаковка объектов.
В это время git:
- Находит файлы, схожие по размеру и содержанию,
- Формирует из них цепочки, располагая новые и часто используемые объекты ближе к началу,
- Находит разницу (дельту) между объектами в цепочке,
- Последовательно сохраняет цепочки в pack-файл, причем второй и последующие элементы цепочки записываются как дельта относительно предыдущего объекта.
Алгоритмы git отточены и оптимальны, поэтому такая запаковка значительно оптимизирует хранение объектов. Полученные pack объекты хранятся в папке objects/packs, причем один pack объект порождает два файла: .pack, состоящий из сжатого содержимого, и .idx, позволяющий быстро находить требуемые объекты.
Аналогично, указатели могут сжиматься в один файл, называемый packed-refs. Такое изменение оптимизирует процедуру поиска для файловой системы.
Интересный факт. Если вы изменяете указатель, который был сжат в packed-refs, то он не будет удален из этого файла. Просто в папке refs/… появится соответствующий файл. Это наглядно демонстрирует особенности процедуры поиска указателей. Сначала проверяется существование его в папке refs и если он был найден, то поиск завершается, что логично. Потом же он ищется в packed-refs. Если результатов обнаружено не было, git выдаст ошибку.
Вообще, если задуматься, то описанные выше факты про свободное хранение и packed-refs прямо показывают, что git построен так, чтобы иметь максимальную скорость выполнения команд.
То есть при изменении какого-то указателя у вас не будет изменяться файл, в котором могло быть довольно много строк.
Как легко догадаться, все изменения, созданные в свободном формате, будут сохранены при запуске git gc — garbage collector’а или сборщика мусора.
Логирование изменений или logs
Git поддерживает список изменений, вносимых в указатели (и, в том числе, HEAD), причем делает это в обычном текстовом файле, находящемся в папке logs. Возникает логичный вопрос, а зачем это нужно?
Вы должны помнить про состояние detached HEAD.
Даже учитывая все предупреждения, которые выдает git, упустить какие-то изменения может быть нетрудной задачей.
С помощью команды git reflog, которая своим названием подсказывает, что это лог изменений указателя, можно узнать с какого и на какой коммит менялся тот или иной указатель.
Таким образом можно восстановить затерявшиеся изменения.
Важно знать, что содержимое папки logs не отправляется на сервер. Оно существует локально у каждой копии репозитория.
Как казалось ранее, команда git update-ref лишь меняет содержимое файла и это можно было сделать «руками».
Потом, мы узнали, что она выполняет некоторые проверки во избежание ошибочных присваиваний.
Сейчас же самое время сказать, что она еще вносит изменения в reflog.
Посмотрим на reflog для HEAD, получившийся во создания и работы с репозиторием.
$ git reflog HEAD
9673595 (HEAD -> master, tag: first-commit-lw, tag: first-commit) HEAD@{0}: checkout: moving from ca84f5a1ec1ae427566540b3c85af2da56fc85e7 to master
ca84f5a HEAD@{1}: commit: second commit (by porcelain)
9673595 (HEAD -> master, tag: first-commit-lw, tag: first-commit) HEAD@{2}: checkout: moving from master to first-commit
9673595 (HEAD -> master, tag: first-commit-lw, tag: first-commit) HEAD@{3}:
Самые старые записи находятся снизу. Сначала мы изменили HEAD путем изменения refs/heads/master на 9673595. Потом мы переключились на detached HEAD состояние. Далее создали коммит porcelain командами и вернулись в нормальное состояние командой git checkout.
Вы можете заметить обозначение HEAD@{1}, если обобщить, то ref@{n}. Это запись, позволяющая обратиться к коммиту, в состоянии которого был указатель ref n изменений назад. Например, HEAD@{0} — обращение к текущей версии указателя HEAD. Как вы могли догадаться, для этих обращений используется reflog, поэтому они могут отобразить только локальные изменения указателей.
Важно уточнить, что данные в reflog со временем устаревают и удаляются при вызове git gc (или команд, которые его вызывают).
Обычно, срок хранения всех объектов и изменений составляет 2 недели.
Как устроена командная работа
Git является СКВ третьего (распределенного) поколения. Вообще, из этого нас интересует, что он не является системой первого (локального) поколения. Получается, git предусматривает какие-то механизмы обмена информацией между пользователями. Логично предположить, что это достигается посредством какого-то сервера, с которым будут общаться пользователи.
В настоящее время таких серверов, причем доступных бесплатно (ограниченно, но все же) любому пользователю, очень много. Популярный и известный всем github, многофункциональный gitlab, bitbucket и многие другие. Также существуют отдельно разрабатываемые self-hosted решения, например, gogs и его форк gitea.
Вообще, git сервер не обязан иметь web-интерфейс.
Есть три протокола, по которым клиент может общаться с сервером: git, http и ssh.
Первый способ очевиден — на сервере есть процесс (который можно запустить командой git daemon), который и общается с клиентом.
Его минусом является полное отсутствие авторизации.
Второй и третий способ можно встретить в ранее перечисленных серверах.
В этих случаях используются специальные скрипты, которые принимают отправленные пользователем изменения.
bare репозиторий
Еще раз вспомним, что git — распределенная СКВ, поэтому все копии репозитория равнозначны. Конечно, в процессе работы может нарушаться их идентичность, в некоторых репозиториях могут отсутствовать какие-либо изменения. Например, такое может произойти, когда вы создали коммит локально, но еще не отправили его на сервер. Git не требует полной идентичности всех копий, что позволяет удобно коллаборировать в процессе разработки.
Как легко догадаться, git репозиторий (содержимое папки .git) должен уметь синхронизироваться с сервером.
Логично, что для этого удобнее всего будет иметь на сервере точно такой же репозиторий.
Также очевидно, что на сервере никто с содержимым работать не будет, поэтому репозиторию не требуется working tree.
Так мы и пришли к ответу на вопрос: «что такое bare репозиторий»?
Формально говоря, это содержимое папки .git на локальной машине, от которой он отличается лишь строкой bare = true в config файле репозитория.
Работа с удаленными репозиториями
Для управления списком удаленных (которые на сервере, а не в корзине) репозиториев используется команда git remote.
Документацию по этой команде можно найти здесь.
Необходимо упомянуть об изменениях во внутреннем устройстве репозитория.
Во-первых, появится запись о remote репозитории в config файле (и, если отсутствовал, сам файл).
Во-вторых, при первой синхронизации появятся новые указатели в папке refs/remotes/<remote_name>.
Более, кардинальных изменений не будет, максимум информация в info / логах, но она не так критична для понимания.
То есть, удаленный репозиторий это лишь пара строчек в конфигурации (с указанием, где он находится) и дополнительные указатели на состояние веток в remote репозитории.
Зачем вообще нужно иметь состояние remote веток? Это является удобным методом синхронизации и разрешения конфликтов. Логично, возникает вопрос, а что такое конфликт? Бывают случаи, когда в один и тот же файл разные пользователи вносят изменения независимо. Потом, один из них получит изменения другого с удаленного репозитория и, при попытке синхронизировать их со своим локальным репозиторием, получит merge conflict. В таких случаях придется выбрать, какие изменения в файл нужно сохранить. Эта процедура называется conflict resolving или решение конфликтов. Но не только по этой причине удобно разделение на remote и local ветки. Оно позволяет вам получить изменения, отсматривать их на локальной машине, но не применять их в вашу рабочую ветку. Такая ситуация может возникнуть, например, при желании доделать фичу, а только потом уже смержить ветки, но изменения нужно посмотреть уже сейчас и сделать это можно только локально.
Использование git на полную
Вообще, git обладает множеством настроек и фишек, которые могут облегчать и улучшать его использование. Например, все, кто хоть немного работал с git, знают про файл .gitignore. Если же вы не слышали, то можно прочесть о нем здесь. Говоря в общих чертах, это файл конфигурации, говорящий git, какие файлы не стоит версионировать. В него обычно заносят файлы по типу .idea (конфигурации сред разработки), .DS_Store (файлы, специфичные для ОС), target, build (результаты сборки кода).
Временное хранилище изменений или stash
Пусть сложилась такая ситуация: вы разрабатывали фичу, но не успели ее завершить. В какой-то момент вас вызывает начальник и говорит, что срочно нужно внести мелкий фикс в старую версию. Как поступить, чтобы не создавать коммит с текущими изменениями, ведь все равно еще ничего не работает?
Выходов, конечно, много. Заново склонировать репозиторий, создать commit в состоянии detached HEAD, а потом его удалить (выполнить reset). Это, конечно, выходы, но у гит есть удобный инструмент, называющийся stash. Он представляет собой стек, в который вы временно можете положить изменения.
В данной статье мы не будем разбирать, как им пользоваться, документация это хорошо описывает. Нам интересен факт внутреннего устройства. Наверное, вы удивитесь, но git stash создает объекты типа commit. Невероятно! Почему это возможно?! Как вы помните, коммит попадает в историю лишь тогда, когда достижим по какому-либо указателю. Конечно, stash создает свой указатель refs/stash (зачем, узнаете уже совсем скоро). Но этот указатель никогда не покидает ваш локальный репозиторий. Можно считать, что stash это отдельная ветка (что тоже не полностью верно), которая является строго локальной.
Во-первых, надо разобраться, в какой форме хранятся состояния stash. На картинке, приведенной ниже, все ясно видно.
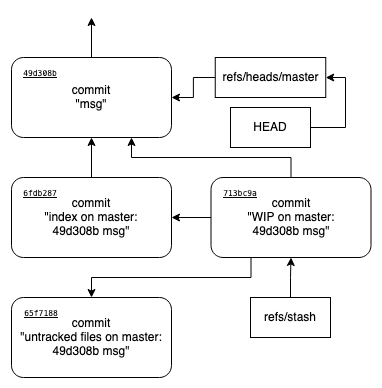
Создается коммит, содержащий состояние index на момент занесения в stash, для которого родителем является текущий коммит из HEAD. Далее создается коммит, который сохраняет все untracked файлы. Если таковых нет, он не создается и далее в процессе его хеш просто опускается. Далее создается коммит, соединяющий три коммита: изначального, состояния индекса и, если существует, состояния неверсионируемых файлов. Указатель refs/stash теперь указывает на него. Заметьте, нигде здесь не указывается предыдущий коммит stash.
Во-вторых, нужно понять, происходит сохранение последовательности коммитов stash. Если бы это был односвязный список, как обычно, то все было бы очевидно. Тут же используется особенность stash — локальность. Подсказка: обратиться к самой верхнему сохранению можно через stash@{0}, к предыдущему как stash@{1}. Если вы все еще не догадались, то вам необходимо вспомнить, кто предоставляет такой синтаксис. Это, конечно же, reflog. То есть, git stash использует указатель только для того, чтобы сохранить изменения в reflog. Нетривиальный и идейный подход, не правда ли?
В-третьих, как удаляются объекты после того, как мы вытащили изменения из stash?
Если посмотреть на папку .git/objects после выполнения команды, то окажется, что никак.
Стоит лишь вспомнить, что git gc выполняется время от времени и удаляет все неиспользуемые объекты.
На этом особенности внутреннего построения stash закончились.
Репозиторий в репозитории или submodules
Иногда возникает необходимость подключить какой-то репозиторий в свой репозиторий в качестве папки. Простой пример: библиотека на python, не загруженная в pypi. Конечно, можно просто скачать код и положить в нужную папку, но это будет очень сложно поддерживать.
Git предоставляет возможность сделать это удобно, нужно лишь, чтобы у репозитория был какой-то адрес. Про то, как это все настраивается, можно почитать здесь.
Как это устроено?
Ребро папки (или строчка вида 040000 tree d00491fd7e5bb6fa28c517a0bb32b8b506539d4d repo), в которую встраивается репозиторий, в представлении дерева будет не tree (040000), а gitlink (160000).
Указывает этот gitlink на хеш коммита, состояние которого необходимо текущему репозиторию от дочернего.
Еще будет создан файл .gitmodules в корне working tree.
Он содержит название модуля и url, откуда он клонируется.
Обычно, но не всегда, репозиторий клонируется в .git/modules, а в папку, в которой он должен находится, на замену .git создается ссылка (ярлык).
Советы по дальнейшему изучению
Как вы могли заметить, в статье было сказано очень мало про работу с git в консоли.
Конечно, автор много чего еще хотел изложить, но ….. тогда статью можно будет осилить лишь за несколько часов, а это уже не приятно.
Да и писать такую статью не является легкой и быстрой задачей.
Вообще, знаний, которые вы получили за статью, будет достаточно, чтобы осознать из документации, как работает большинство команд.
Конечно, искать статьи с разбором команд в интернете, но умение читать и понимать документацию формата man является важным навыком.
Найти ее можно, как ни странно, запросив у команды man, например, man git, man git-commit, man gitrepository-layout.
Но это не всегда бывает удобно, поэтому можно поискать ее на официальном сайте.
На этом же сайте есть книга Pro Git, рекомендацию к прочтению которой я давал в статье.
Для практики porcelain команд по работе с ветками (про которые в статье почти не говорилось), предлагается выполнить упражнения на сайте. Также не было сказано про модификаторы указателей, но это, опять же, есть в этом игровом сайте.
Тут также не было сказано про CI/CD и работу с git серверами, про это автор постарается сделать еще одну статью.
А, вообще, для успешного использования и понимания git надо просто использовать его. Удачи!